UI-First
Build pipelines visually with a modern drag-and-drop editor
Kafka Connect Plugins
Integrates seamlessly with the Kafka Connect ecosystem
Batteries Included
Built-in monitoring, error handling, and health checks
Decentralized
No central coordinator. Each instance runs independently
Streemlined in 60 seconds
Where does Streemlined fit the ecosystem?
Kafka Streams and Spring Kafka give teams autonomy, but demand Java expertise. Shared Kafka Connect clusters are no-code, but centralized and dependent on a platform team. Streemlined is both: the simplicity of Connect with the independence of Streams, letting any team own their pipelines end-to-end.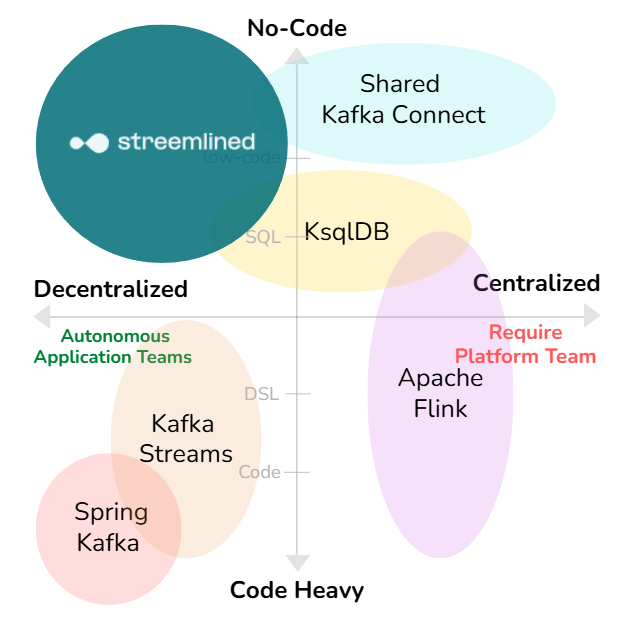
When to Use Streemlined
Streemlined shines when you need to move fast and ship reliable pipelines without a dedicated streaming team:- Fan-out to multiple sinks — one topic, many destinations: databases, search indexes, warehouses, APIs
- Real-time enrichment — hydrate events with lookups from HTTP services or caches before they land
- State-store — maintain key-value state across events for deduplication, caching, or lightweight aggregations
- Smart routing — split, filter, and route messages based on content to different topics or systems
- Protocol bridging — connect Kafka to anything with REST, JDBC, or the 200+ Kafka Connect plugins
- Self-service streaming — let product teams own their data flows without waiting on platform engineers
When to prefer other options
Streemlined deliberately trades off advanced stateful capabilities for simplicity. If your use case requires any of the following, consider Kafka Streams or Flink:- Windowed aggregations — time-based grouping, tumbling/sliding windows, session windows
- Stream-to-stream joins — correlating events across multiple topics by key and time
- Exactly-once across multiple outputs — transactional writes spanning Kafka and external systems
Next Steps
Quickstart
Build your first pipeline in 10 minutes
Core Concepts
Understand pipelines, nodes, and JSONata